
Effects of Using Neural Networks to Generate Music
 Author: Kevin J. Wang
Author: Kevin J. Wang
(Student of The Webb Schools, Winner of 2023 Brown University Book Award and 1st Place, Southwestern Youth Music Festival, Chopin Category)
Claremont, California
Abstract:
The objective of this project is to discover the effect of using Neural Networks in AI to generate piano music. Music is sentimental and emotional. In this project 1) I am exploring if AI-generated music can resonate with human emotions; 2) would the AI-generated music comply with music theory. This can be a popular tool for everyone to use to personalize their own music without any composing knowledge.
The 88 piano keys (52 white and 36 black) are converted to numbers, and pitch value (single note or chords) and duration (the time for which the note is held) are tokenized. AI can produce notes based on the combination of numbers and tokens. To comply with music theory, I use the Concise Oxford Dictionary to check the harmony of the notes and expression of emotions. I used Long-Short Term Memory (LSTM) of recurrent neural networks in Python with the TensorFlow platform and Keras model to create an application that can play and compose music on its own. The model is able to take a sequence of inputs and predict the best fit for the output based on the creativity parameter.
The effect of AI to generate piano music by using Neural Networks is confirmed powerful. The model has achieved great results and is able to demonstrate music theory knowledge.
Although the AI-generated music seems coherent, there is future work to be done to eliminate some randomness in the music and add more creativity, along with a clear distinction between different eras of music.
Table of Contents:
- Introduction
- Methods/Architecture
- Results
- Discussion
- Future Work
- References
- Supplemental Material
1. Introduction
The usage of neural networks has had a considerable rise in popularity over the past decade. The main advantage of artificial neural networks is their ability to model nonlinear complex relationships between multiple variables, detect all possible interactions between these variables, and predict, suggest, and map the best connections between these variables (Yu, 1996). The name, “Neural Networks,” references the process by which the human brain works, attempting to mimic its functions and actions. Neural networks are widely used in pattern recognition, such as handwriting recognition, face recognition, text translation, and medical diagnosis (Croak & Dean, 2021). These pattern-based applications can be tested to validate the outcome generated by the neural network model. In other words, it can be determined whether the model was successful at predicting the output based on the final product.
Music, unlike medical diagnosis and text translation, is a much more sentimental art form—it is created, formed, reshaped, and constantly adapted to evoke emotions. Determining whether a piece of music sounds “good” or “bad” depends on the listener, resulting in a subjective opinion. Music does not have any testable data to determine whether it is “right” or “wrong.” The objective of this project is to investigate the effects of neural networks on generating music. Two questions arise: Can neural networks generate music that resonates with human feelings? Would the generated music follow music theory?
In this paper, I design an application to answer the above two questions using Long-Short Term Memory (LSTM) recurrent neural networks with the Tensorflow framework in Python.
2. Methods/Architecture
The 88 piano keys (52 white and 36 black) are converted to numbers, and the pitch value (single note or chords) and duration (the amount of time for which the note is held) are tokenized (Fig. 1). The pre-trained model I used from TensorFlow has the ability to comply with music theory, called reinforcement learning. It follows certain rules: to stay in key, avoid excessively repeated notes, begin and end with the tonic note, prefer harmonious intervals, resolve large leaps, etc (Jaques, 2016). Notes based on the combination of number and tokens can be produced, and by using the library Music21 the harmony of the notes can be checked. I used a pre-trained Keras model in Python with the TensorFlow platform to create an application that can generate and play music on its own (Tensorflow, n.d.). I use three variables to represent a note: pitch, step, and duration. The “pitch” is the perceptual quality of the sound as a MIDI note number. The “step” is the time elapsed from the previous note or start of the track. The “duration” is how long the note will be playing (in seconds) and is the difference between the note end and start times. I chose five different types of MIDI songs for my experimental data and used these as an input source to model in order to generate corresponding output songs, as neural networks predict the output based on input parameters. Then, I developed a Python user interface (UI) to display the parameters I used to generate the songs (see Fig. 2).
Fig. 1. Tokenized Piano Keyboard (Shutterstock, n.d.).
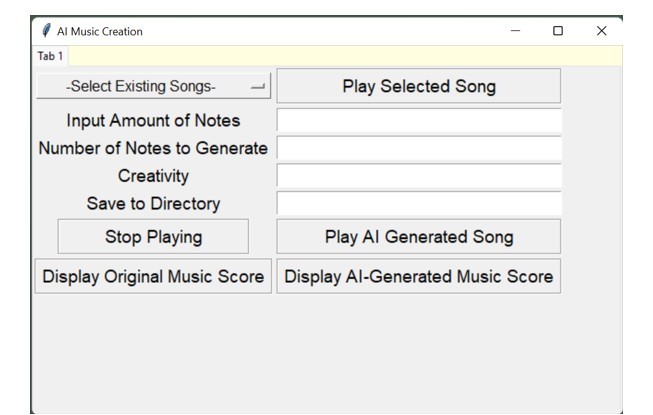
Fig. 2. UI for Music Generator.
The drop-down menu “Select Existing Songs” has a selection of MIDI songs; “Input Amount of Notes” uses a number of notes as a sequence to be the input of the model; “Number of Notes to Generate” is the number of notes to generate as output; “Creativity” is the dynamic output that can be generated from a scale of 1-10, with 10 being the highest; “Save to directory” allows the AI-generated songs to be saved. To be able to compare the AI-generated songs to their corresponding original songs, I developed features to display the original music scores and the AI-generated music scores, so that the user can easily visualize the changes AI made, analyze the changes, and recognize patterns. I further evaluated the music scores using my own music theory knowledge.
3. Results
The effect of artificial intelligence to generate music using neural networks is confirmed powerful, and there have been coherent results with enjoyable melodies from the five AI-generated songs. Five total AI-generated music scores are attached at the end of this report in the Supplemental Data section. These five songs all use the right key signature, the correct tempo, and the correct harmony. Fig. 3 showcases two various music scores.

Fig. 3. Music Scores of the Original Song (Above) and Generated Song (Below)
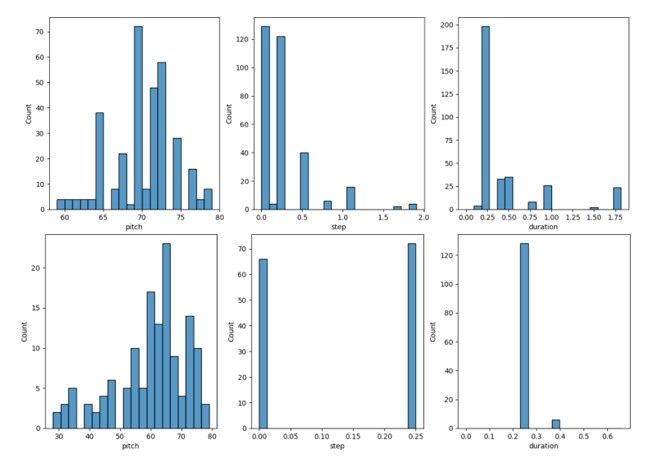
Fig. 4. Count vs. Pitch, Count vs. Step, and Count vs. Duration graphs for Original Song (dayafter.mid) (above) and Generated Song (based on dayafter.mid) (below)
In Fig. 4, it can be seen that the AI-generated songs are denser on the pitch, but there is not enough variety on the “step” and “duration.” The pitch count is a lot more in the generated songs. The original song tends to have higher-pitch notes, as indicated by the pitch level between 60-80, but the pitches of the generated song seem to be more spread from low to high pitches (30-80). The generated songs only have 2 types of steps and a majority of one duration which is far less than the original songs.
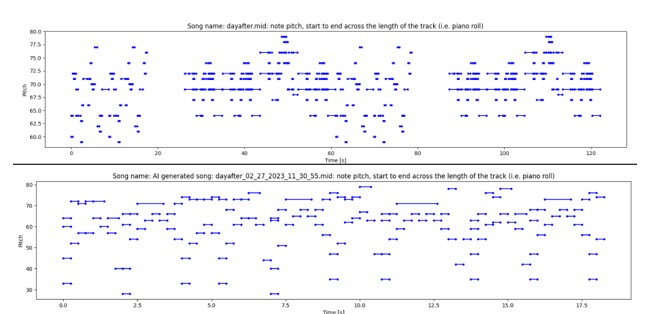
Fig. 5. Pitch vs Time (s) of the Original Song (above) and Generated Song (below).
On the other set of piano roll graphs (Fig. 5), the pitch of the original song has different lengths in terms of time, but the AI-generated song is more evenly spread out throughout the entire piece, with about the same length of the pitch. This further shows the lack of variety in the dynamics of the generated songs. Based on the pattern, it can be recognized that this is AI-generated due to its similarity in length.
4. Discussion
Although using LSTM recurrent neural networks to generate music produces coherent music with a correct key signature, tempo, and harmony, there is still future work to be done to eliminate the slight randomness in pitch in the generated music, as well as a clear distinction of different genres of music. The beginning and end in a generated music piece are not well defined as the current model does not know where the piece ends and another begins—currently, the generated piece ends abruptly. Music generated with artificial neural networks seems to have stronger intensity with a more centralized pitch but lacks variety in color. The tempo is also faster. It can be seen that AI-generated songs are denser on the pitch, but there is not enough variety on the “step” and “duration”. This causes the generated music to have more intensity and has a strong effect of appealing to feelings but a lack of variety of different colors. The lack of variety in the step and duration is due to the limitation of the model.
The original song tends to have higher-pitch notes, as indicated by the pitch level between 60-80, but the pitches of the generated song seem to be more spread from low to high pitches (30-80). High-pitch notes bring about strong feelings. The human brain is more stimulated by high-pitch sounds (Chau et al., 2016). With more notes added to the generated songs, the tempo is faster compared with the original song. On the other set of piano roll graphs (Fig. 3), it can be seen that the original song’s pitch has different lengths in terms of time, but the AI-generated song is more evenly spread out the entire piece with about the same length of the pitch. This further shows the lack of variety in the dynamics of the generated songs. Based on the pattern it can be recognized that this is AI-generated due to its similarity in length.
5. Future Work
There is future work to fine-tune recurrent networks with reinforcement learning which sounds promising to address these issues (Jaques et al., 2016). The fine-tuning technique described in the paper by Jaques et al. (2016) will significantly reduce unwanted behaviors and failure from the generated songs and make the ending smooth. Music theory provides us insight into what note intervals best fit the style, which sets of notes belong to the same key, and how to adhere to relatively well-defined structural rules. Future research will enable the AI model to further comply with these music-theory-based constraints but also maintain its versatility and creativity.
6. References
Chau, C.-J., Mo, R., & Horner, A. (2016). The emotional characteristics of piano sounds with different pitch and dynamics. Journal of the Audio Engineering Society, 64(11), 918–932. https://doi.org/10.17743/jaes.2016.0049.
Croak, M., & Dean, J. (2021, November 18). A decade in deep learning, and what’s next. The Keyword. Retrieved February 16, 2023, from https://blog.google/technology/ai/decade-deep-learning-and-whats-next/.
Jaques, N. (2016, November 9). Tuning Recurrent Neural Networks with Reinforcement Learning. Magenta. Retrieved February 17, 2023, from https://magenta.tensorflow.org/2016/11/09/tuning-recurrent-networks-with-reinforcement-learning.
Jaques, N., Gu, S., Turner, R. E., & Eck, D. (2016). Generating music by fine-tuning recurrent neural networks with reinforcement learning.
Shutterstock. (n.d.). [Keyboard Layout of a Piano]. Retrieved January 3, 2023, from https://www.shutterstock.com/image-vector/piano-keyboard-diagram-layout-on-white-1214223253.
TensorFlow. (n.d.). Generate music with an RNN: Tensorflow Core. TensorFlow. Retrieved February 16, 2023, from https://www.tensorflow.org/tutorials/audio/music_generation.
Tu J. V. (1996). Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. Journal of clinical epidemiology, 49(11), 1225–1231. https://doi.org/10.1016/s0895-4356(96)00002-9.
7. Supplemental Material
dayafter_AI_02_27_2023_11_30_55.pdf

Cids_AI_02_27_2023_11_27_16.pdf

cosmo_AI_02_27_2023_11_42_38.pdf

FF8_Shuffle_AI_02_27_2023_12_40_26.pdf

FFIX_Piano_02_27_2023_12_34_33.pdf

Kevin J. Wang is a high school student passionate about the intersection between computer science and music. He has won several major awards at international, state, and regional piano competitions and has developed many computer science related projects. He is also interested in podcasting, being a co-host and lead producer for his school’s podcast.












